
湖倉一體解決方案
IBM watsonx.data 是 IBM watsonx平台中扮演收集、儲存、查詢和分析的現代化資料基礎架構平台。基於湖倉一體架構理念,watsonx.data 融合了資料倉儲對於標準化資料模型結構的可控性和高品質,以及資料湖的低成本儲存和擴展靈活性。它可以讓企業輕鬆地存取跨雲端和本地環境中的所有資料,並利用多個查詢引擎來執行分析和AI工作負載,同時降低建置實體資料倉儲系統的成本。watsonx.data 不僅可以幫助數據驅動型企業有效降低資料儲存成本,還可以優化人工智慧運算的能力。無論是面對海量數據、複雜度、成本還是治理等相關挑戰,watsonx.data 都能夠協助企業輕鬆應對。
功能優勢
適用於各種使用場景的查詢及分析引擎
watsonx.data內建Presto與Spark引擎,可以為資料湖倉(Data Lakehouse)提供快速、可靠、高效能的資料查詢及分析能力,企業可以依據不同的使用情境選擇合適的引擎來處理工作負載(例如:BI 報表與即時分析、AI 機器學習建模應用)。
- Spark:業界知名的開源數據分析引擎,適用於數據工程、數據科學和機器學習等工作負載。
- Presto:開源、分散式架構 SQL 查詢引擎,專為大規模數據運行快速且高效的分析查詢設計。
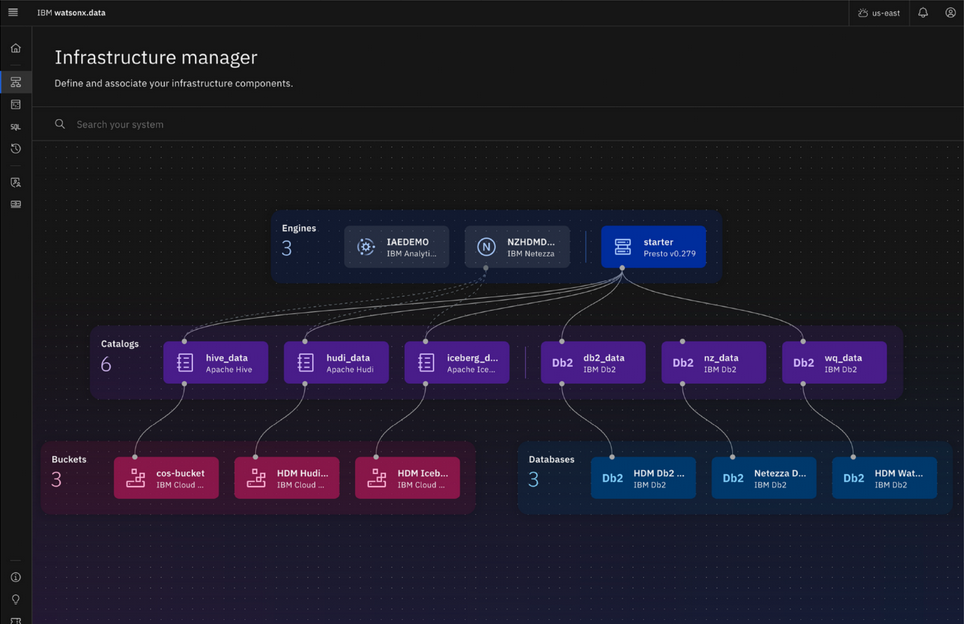
開放、可擴展式的資料表格式
watsonx.data支援Avro、Parquet、ORC等開放式檔案儲存格式,同時使用適用於大規模資料處理和分析的Apache Iceberg高性能資料表格式來建立共用的中繼資料層,這使得不同的引擎能夠同時存取和共享資料。Apache Iceberg具備以下的特性:
- 為 Data Lake 數據帶來 SQL 的可靠性和易用性。
- 允許多個查詢引擎同時存取相同的資料表。
- 支持 ACID 特性,確保交易數據的一致性。
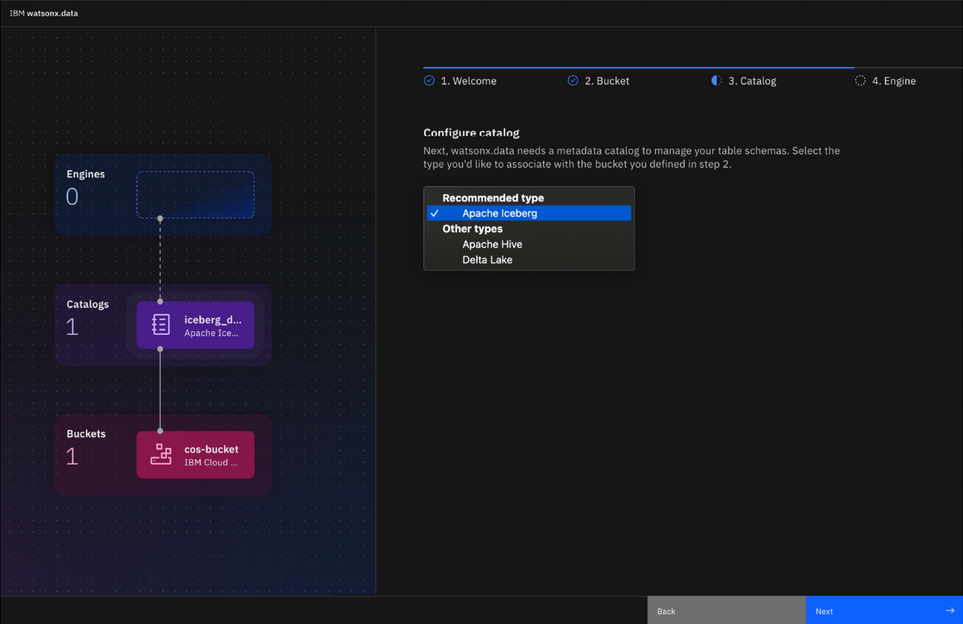
內建元數據管理和安全性存取控制功能
watsonx.data內建Apache Hive Metastore來管理元數據和安全性,同時亦提供對元數據目錄、血緣關聯以及數據存取控制等全面性管理功能,滿足企業對於資料存取、隱私安全、以及法規遵循相關的資料治理要求。此外,watsonx.data亦支援與IBM Watson Knowledge Catalog資料治理解決方案無縫整合,使用者透過單一入口即可共享企業資料資產。
- 加速整理大量既有數據,創建知識目錄與數據標準。
- 以系統性方法落實數據治理流程、隱私政策、存取規則。
- 自動執行數據探索並持續追蹤與確保數據品質。
支援混合雲部署與經濟高效物件存儲架構
結合Red Hat OpenShift 容器管理,watsonx.data架構支援以混合方式部署於雲端與地端環境,讓使用者可以從任何地點存取數據,同時亦需要依據實際使用量的增加進行資源的彈性擴充。此外,企業可以利用簡單的物件儲存庫(Object Stores)以簡約的成本即可儲存大量數據。
- 無需再為資料倉儲儲存空間大小煩惱。
- 支援分散式架構提供高可用性儲存服務,數據可於分散式節點中自動產生冗餘副本避免數據損失。
- 物件儲存服務相對成本低,可選擇的供應商較多,亦可避免被單一廠商綁定。
預期效益
實現更高效的 AI/ML 模型部署
在 watsonx.data 中建立、訓練、調整、部署並監控用於關鍵任務工作負載的可信人工智慧和機器學習模型;加強對用於人工智慧的數據的血緣和可重現性的合規性。
實現更即時的商業智慧分析
將既有資料倉儲中的數據與 watsonx.data 中的新數據結合,快速地產生新的業務洞察與見解,無需在不同環境之間複製和搬移數據,降低開發成本與維運複雜性。
實現更簡潔的數據工程流程
簡化數據擷取、轉換、載入等數據工程流水線作業,使用合適且熟悉的 SQL 與Python 技術或融合生成式人工智慧的對話界面,創造更豐富且友善的使用體驗。
實現更信賴的數據共享環境
透過集中式的數據治理與政策執行能力,強化對數據使用的安全性與合規性控制,讓更多使用者都可以透過自助查找方式取得數據、運用數據來創造企業競爭價值。
