
IBM BigInsights 為企業海量資料賦予意義
大數據喊了那麼多年,已不再是趨勢,它是現實,充斥你我身邊。
大數據的力量早已為企業界所熟知,但該如何具體落實創造效益呢?當億兆訊息奔騰流動,甚麼樣的架構平台才能精準定格每一個當下,創造變革商機?
大數據 4V特性
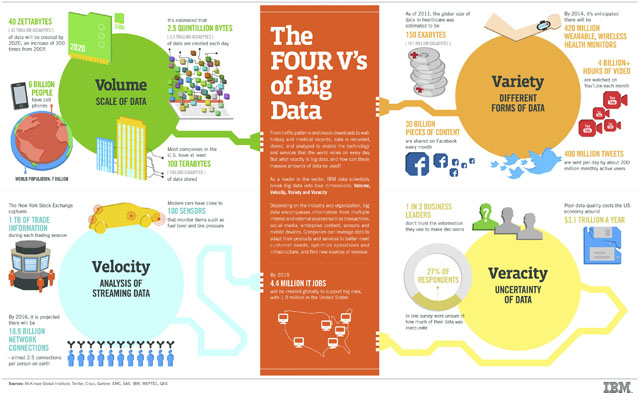
早在2010 年IBM便所提出海量資料(又稱大資料、大數據)即《Big data》,而海量資料則的特性包含三種層面:巨量、即時性及多樣性。
- 巨量性(Volume) – 海量資料的特色就在於: 龐大。為了提高整個企業的決策,組織試圖利用龐大資料。而這些資料很容易便達到數TB(Tera Bytes),甚至上看PB(Peta Bytes)之譜。
- 即時性(Velocity) – 海量資料通常具有時效性,一旦串流到運算伺服器就須立即使用,即時得結果才能發揮其最大價值。
- 多樣性(Variety) – 海量資料的範疇不僅止於結構化資料,還包含各類非結構化的資料: 諸如文字、音訊、視訊、點擊串流、日誌檔等等。
而在2012年IBM更提出第四個重要的面向:真實性(Veracity)。將真實性作為第四個大量資料屬性,強調了對某些類型的資料所固有的不確定性進行處理和管理的重要性。
挑戰還是機會?
海量資料不只是一項挑戰,更是絕佳的機會,讓您能夠洞悉新興的資料類型、使企業運作更加靈敏並為過往所無法企及的問題提供解答。 但在此之前,這種機會並無實際方法可以掌握。 今天,IBM 的海量資料平台採用Hadoop 等技術,能為充滿各種可能性的世界開啟一扇大門。
IBM InfoSphere BigInsights 企業版
IBM InfoSphere BigInsights Enterprise Edition(企業版)讓企業創造新解決方案,以符合成本效益的方式,洞察大量複雜資料的意義。此分析平台符合企業需求,結合Apache Hadoop與 IBM 獨特創新技術,具復原與容錯能力,能處理、分析大量的擴充式(scale-out)資料。
提升海量資料 (Big Data) 分析的安全性
企業對安全有非常嚴格的要求,InfoSphere BigInsights 可精密調整,維護資料安全與隱私。
- 身份驗證
InfoSphere BigInsights 主控台可選擇純文字檔、輕量型目錄存取通訊協定(LDAP) 或未驗證。有了LDPA 驗證,InfoSphere BigInsights 安裝程式能與LDAP 憑證儲存庫聯繫,進行驗證,接著,管理者可根據使用角色成員資格,設定使用者群組存取InfoSphere BigInsights 主控台的權限。 - 授權
InfoSphere BigInsights 根據使用角色,提供 4 個層級的使用者授權:系統管理員、資料管理員、應用程式管理員與非管理使用者;使用者存取資料與功能的權限,視其角色而定。
提升效能,簡化工作處理
IBM 新增數種功能,可提高效能,讓InfoSphere BigInsights 更具彈性且能相容於企業環境。
- BigInsights Scheduler 配置工作流程
並非所有工作都優先順序都相同,BigInsights Scheduler (排程器)提供MapReduce 工作可調整的工作流程配置方案,根據使用者選擇的原則,最佳化處理。排程器是Hadoop Fair Scheduler 的延伸套件,能爲所有工作公平分配叢集資源。 - BigIndex 支援大型索引編製
BigInsights 納入BigIndex 功能,讓Hadoop 索引編製更為容易。BigIndex 以 Apache Lucene 為基礎 , 在海量資料(Big Data) 中提供快速的全文搜尋,在工作流程中運用BigIndex 模組,能編製、掃描與查詢索引,以及其他複雜功能,如分散式索引編製(Distributed Indexing) 與多面向搜尋(Faceted Search),讓自訂應用程式開發與搜尋技術選擇更有彈性。 - Adaptive MapReduce 加速完成工作
在InfoSphere BigInsights 上執行的工作,經常建立多個小型作業,耗用大量系統資源,有鑑於此,IBM 發明了Adaptive MapReduce 技術,改變MapReduce 處理工作的方式,但不改變建立工作的方式,加速完成小型作業;Adaptive MapReduce 完全不影響MapReduce 與Hadoop API 作業。
運用分析加速器,深入分析海量資料(Big Data)
InfoSphere BigInsights 包含眾多分析工具與功能,開箱即用,可迅速找出資料模式,也能建立強大的自訂分析應用程式,洞察資料、發揮成效,滿足特定企業需求。
- BigSheets
BigSheets 為革命性資料分析工具,以瀏覽器為操作介面,可探索儲存在 BigInsights 叢集的資料,無需撰寫程式碼就能分析資料,內建分析巨集能滿足一般資料探索需求,進一步改善資料存取。BigSheets 協助企業使用者:- 從網頁儲存庫整合龐大的非結構化資料
- 從使用者定義的URL種子,收集各式各樣非結構化網頁資料
- 分析文字,擷取與擴充網頁資料
- 分析使用者定義環境的資料,以圖形呈現
- 進階文字分析加速器(Advanced Text Analytics Accelerator)
BigInsights 包含 IBM 開發的強大文字分析引擎(Text Analytics Engine),IBM Watson™ 便是運用此引擎,在Jeopardy! 機智問答賽中擊敗兩名最優秀的參賽者。開發人員運用無所不包的規則庫 (Library of Rules)(或自訂規則),迅速查詢、辨識文件及訊息中關注的項目,包括人員、電子郵件位址、地址、電話號碼、網址、合資企業、聯盟等。文字分析引擎支援英文、荷蘭文/法蘭德斯語、法文、德文、義大利文、葡萄牙文、西班牙文、日文與中文。 - Jaql
Jaql由IBM開發,為強大、高階的宣告式查詢語言(declarative query language),支援開放標準,能處理結構化與非結構化資料。Jaql介面以類SQL (SQL-like),讓熟悉SQL語言的開發人員輕鬆上手,整合相關資料庫更輕鬆。InfoSphere BigInsights内含預先安裝的Jaql模組,包括Lucene索引、Netezza資料倉儲應用程式系列、Hbase(Hadoop資料庫)與工作流程(包括InfoSphere BigInsights 內建文字分析功能)。
原文出處:
comments powered by Disqus