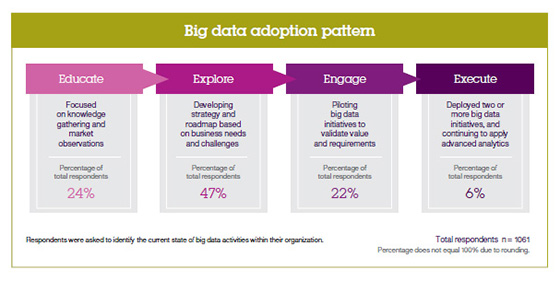
IBM研究機構最近與牛津大學賽德商學院合作,有份研究報告最佳的五個方法來使用海量資料(the top five ways to get started with big data)。依據研究結果,歸類統計出大量資料採用總共分為四個階段:訓練Educate、探索Explore、參與 Engage、執行Execute。參照圖一:大資料採用階段。
從360度看客戶:從內部與外部的資訊資源來延伸既有客戶的觀點。
徹底的了解客戶,得知客戶通常在哪邊買東西,客戶可能會買那些其他的商品。然而這需要公司應用內部與外部資源來評估客戶的喜好,透過關鍵的決策來幫助公司建立與客戶之間的關係。
最近IBM商業價值研究學院報導實際上使用海量資料的案例,建議企業先專注在那些能夠確實了解並預測客戶未來行為的分析海量資料。在這案例中,醫療產業中的病人、政府機關人員或是製造供應商,都能被廣泛定義為客戶。
除此之外,這些分析可提供洞悉客戶的行為,全方位了解客戶,是為了要讓面對客戶的員工與客戶間關係更緊密。企業要有預測的概念,讓員工變成專業的銷售員,透過訓練有素的員工,將對的資訊提供給客戶,建立與客戶之間信賴關係,達成成功銷售,例如:解決客戶的問題、垂直銷售、交叉銷售更多的產品。要達成這個結果,企業必須快速地從沒有資料到取得特定客戶所需要的資料。
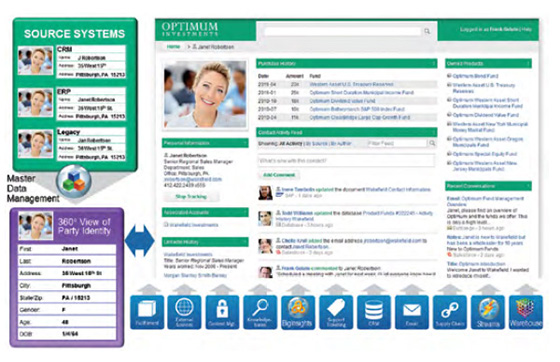
InfoSphere Data Explorer 整合IBM Master Data Management(MDM)從應用程式和儲存庫包含CRM、ECM、供應鏈、訂單存貨系統、和email等等,提供一個整合的介面來檢視客戶資訊,而不需要在登入不同的系統來操作。
這個介面,員工可以看到客戶基本資訊,買哪些產品、目前支援甚麼專案、關於他們公司有甚麼新聞、最近的轉變…等等。從InfoSphere BigInsights和IBM Stream、IBM Cognos business intelligence和IBM SPSS等產品,分析的內容。員工可以透過與客戶互動透過客製化的內容。藉由這樣的此互動,員工可以提供正確的答案給客戶而且也可以增加垂直銷售的機會。
在螢幕的中心顯示關於客戶正在觀看的產品或其他實體的及時動態更新。通過應用程序分析的情況下,從InfoSphere BigInsights、InfoSphere Streams、IBM Cognos BI和IBM SPSS產品內的分析資料,也能呈現分析結果並將其視覺化。這使員工與客戶更有互動,並提供客製化的商品銷售。通過這樣做,他們可以快速提供正確的答案,同時也增加垂直銷售的機會。 圖2/ Information about a customer as viewed in an appliction built with the InfoSphere Data Explorer Application Builder, leveraging InfoSphere Master Data Management for a trusted view of customer data
如圖2中,利用主數據管理可以確保在所有的組織中的各個系統的數據的準確性和可靠性。這種一致性將確保通過的InfoSphere Data Explorer Application Builder,將包含有關實體一致和準確的數據。InfoSphere Explorer提供商業用戶完整的介面,可看到應用程式中的資料並結合其他結構化和非結構化數據的相關內容。
可查詢的數據存儲:在這種方法中,透過使用資訊整合和工具庫,可將應用程式資料庫中的較不常存取或老舊的資料卸載。這有助於將企業較不常接觸的數據,用低成本存儲方式儲存,還可同時使用InfoSphere BigInsights中的查詢或BI工具維持這些資料取得的便利性。InfoSphere Data Explorer 可以用來查看和瀏覽所有已存儲在BigInsights中的InfoSphere數據。